Hallucination Detection
Hallucination detection identifies cases where an AI assistant generates information that is fabricated, unsupported, or contradicts its own previous statements. Oversight checks every assistant turn in a conversation and flags issues with a confidence score and detailed reasoning.
Detection Subtypes
Oversight detects four distinct types of hallucination:
Self-Contradiction
The assistant makes a claim in one turn that directly contradicts something it said in a previous turn within the same conversation.
Example: The assistant says "Your plan includes 10 GB of data" in turn 3, then later says "Your plan comes with 5 GB of data" in turn 7.
Overconfidence
The assistant states uncertain or approximate information as if it were definitive fact, without appropriate hedging language.
Example: The assistant says "The processing time is exactly 24 hours" when the actual time varies based on multiple factors.
Fabricated Citation
The assistant references a specific source, document, policy, phone number, or URL that does not exist or is incorrect.
Example: The assistant says "According to our Terms of Service section 4.2..." when no such section exists, or provides a customer service phone number that is fabricated.
Hardcoded Fact
The assistant states a specific factual claim (date, price, specification, etc.) that cannot be verified against the provided ground truth or known information.
Example: The assistant says "This feature was launched on March 15, 2024" when no source material supports this date.
How It Works
- The conversation is sent to the selected LLM provider (Gemini, Groq, or Both)
- A specialized prompt instructs the model to analyze each assistant turn for the four hallucination subtypes
- The model returns a structured JSON response identifying flagged turns, subtypes, confidence scores, and reasoning
- In Both mode, Gemini runs first, then Groq performs a cross-check — only issues confirmed by both models are retained at the highest confidence
Using Ground Truth
For improved accuracy, you can select a Ground Truth document when uploading a conversation. The ground truth provides factual reference material that the LLM uses to verify assistant claims against known-correct information. This is especially useful for detecting fabricated citations and hardcoded facts.
Reading the Dashboard
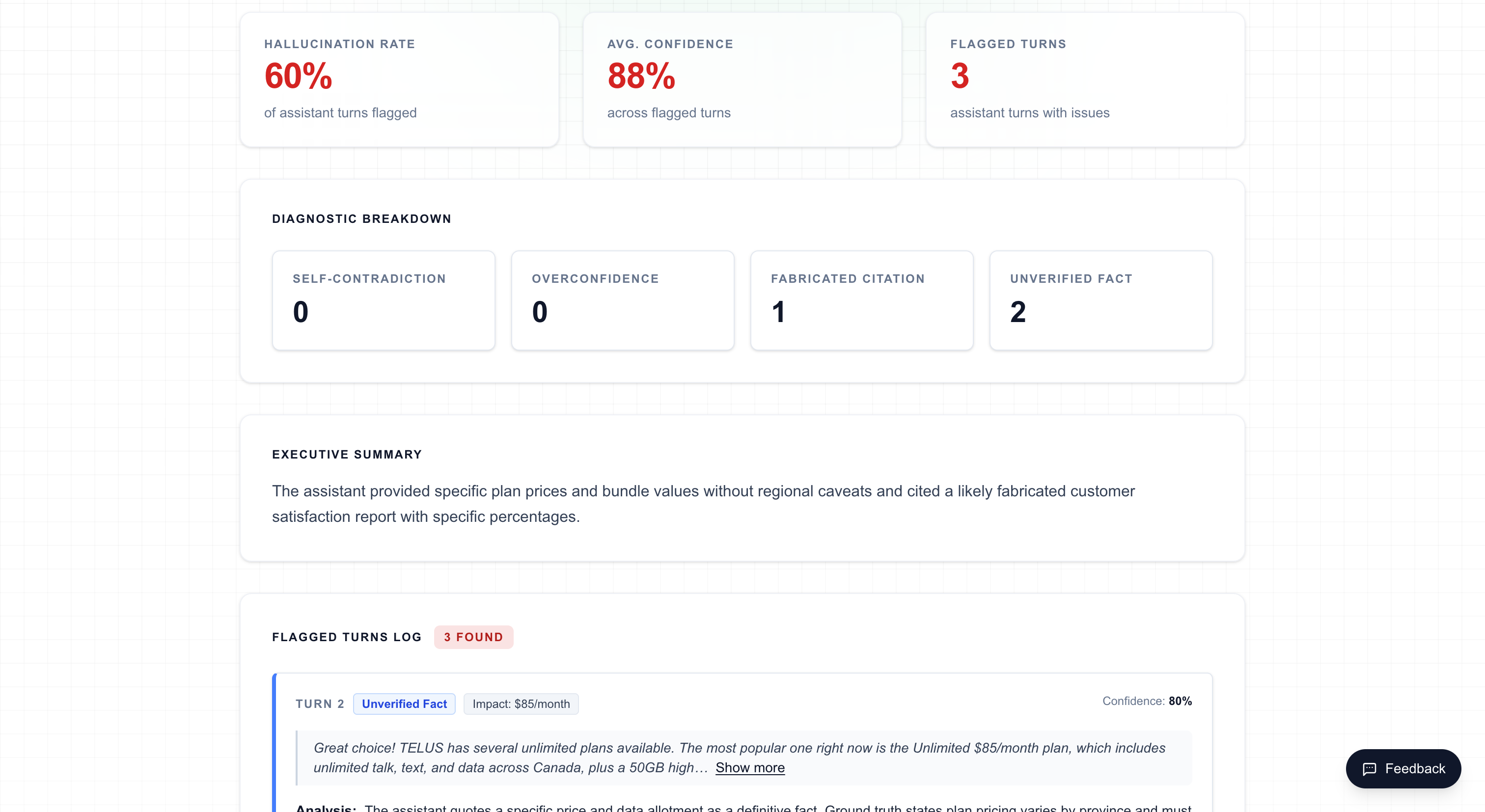
On the analysis dashboard, the Hallucination tab displays:
- Flagged turn cards — Each card shows the user message, assistant response, detected subtype, confidence score (0–100%), and the model's reasoning for flagging it
- Confidence bar — A visual indicator of how confident the model is in the detection
- Provider selector — In "Both" mode, you can switch between Gemini, Groq, and cross-checked results
Tips
- Use Both mode for the highest accuracy — cross-checking eliminates false positives
- Always provide a ground truth document when analyzing domain-specific conversations (e.g., telecom support, healthcare)
- A built-in TELUS Telecom ground truth is available by default for testing